
Ambiguity in user prompts is one of the more significant challenges for Retrieval-Augmented Generation (RAG) systems striving to deliver precise and actionable responses. For any system with impactful consequences, such as medical diagnostics, financial actions, asset management (e.g. cloud computing), and similar domains, it is crucial to develop strategies that can identify, interpret, and resolve ambiguity effectively, ensuring the desired impacts are achieved.
Lets try analyzing sentiment on
“That comedian could not be any funnier”
Asking ChatGPT 4.0:
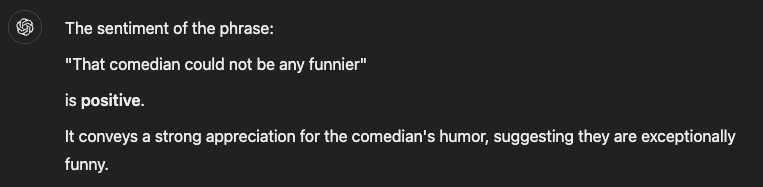
Asking, “Could it be a negative phrase?” sent it into a bit of a shock.
After over half a minute of contemplation, it responded with:

Another, much simpler example can be as follows:
“The customer asked to ‘Buy 100 shares of MSTF”
A simple typo has just made the customer a proud shareholder in Mostotrest, a Russian construction company, instead of MSFT (Microsoft Corporation).
Ambiguity is not always critical. However, as the second example implies, sometimes it is of the essence. The consequences of misinterpretation can often be avoided by implementing a few additional steps to resolve ambiguity. The first and most crucial task in handling ambiguity is recognizing that the instruction is unclear, often due to missing context or misspellings. This issue typically arises at the very beginning of prompt handling and may require several iterations as the agent attempts to establish confidence in the taxonomy, references, and structure of the input.
Three prevalent approaches to disambiguation are:
- Rule-Based Systems
Rule-based systems are custom-tailored to specific domains. This approach is highly precise within its narrow scope, easily explainable, and requires minimal computational resources. However, it comes with significant drawbacks: it is expensive to scale, challenging to maintain, and limited in handling complex contexts and nuanced queries. - Trained Models with Attention Mechanisms
Transformer-based models leverage attention mechanisms to capture context and semantic relationships. These models excel at managing complex contexts, are capable of high degrees of generalization, and are easily scalable. However, they come with trade-offs: they are computationally intensive, lack explainability, and their performance heavily depends on the quality and diversity of the training data. - Semantic Graphs
Semantic graphs use structured representations of meaning and relationships between entities and actions to identify ambiguity. These solutions are domain-specific, provide interpretability through graph structures, and are highly reliable within their domain. However, they have limited coverage outside their predefined domain, can be complex to manage, and require a significant setup effort.
A Hybrid Solution
The methodology we chose to use in CitrusX, combines the strengths of the these three approaches to provide a robust and efficient solution for disambiguation.
We utilize an embedding model with domain-specific knowledge to map our semantic space. By segmenting this space, we generate an ontology graph in which each vertex corresponds to a specific location within the embedding model’s semantic space, and each edge represents a directional relationship with a distinct meaning..
The result is a graph that provides comprehensive coverage of the known semantic domain. This graph is interpretable, adjustable with heuristic fine-tuning, and capable of handling contextual complexity with ease. Moreover, it achieves these capabilities while often being less computationally demanding than transformer-only approaches.
This approach leverages the scalability and contextual understanding of transformer models, combined with the reliability and interpretability of semantic graphs, ensuring a seamless and efficient way to handle ambiguity in Retrieval-Augmented Generation (RAG) systems.

Leave a comment